创建索引和字段 #
一:创建索引 #
- 命令 创建一个叫zch的索引
D:\CS\solr\solr-8.11.0\bin>solr create -c zch
"java version info is 1.8.0_321"
"Extracted major version is 1"
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin\solr config -c zch -p 8983 -action set-user-property -property update.autoCreateFields -value false
Created new core 'zch'
D:\CS\solr\solr-8.11.0\bin>
- 手动创建索引
首先创建一个文件夹
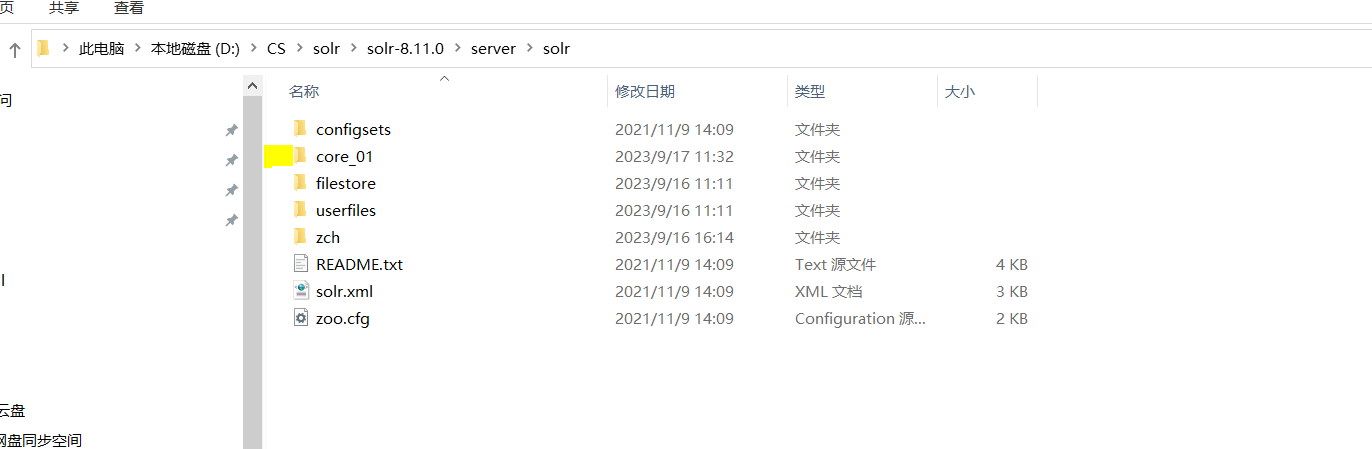

接着 将下面的文件夹所有复制到core_01中
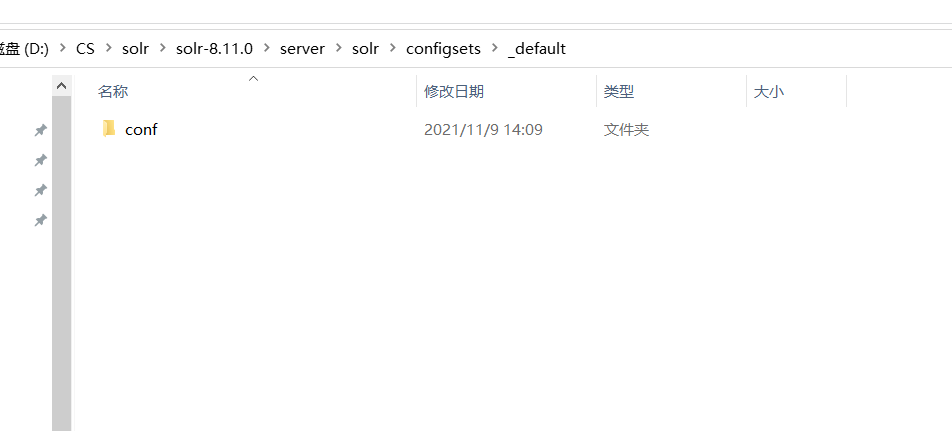

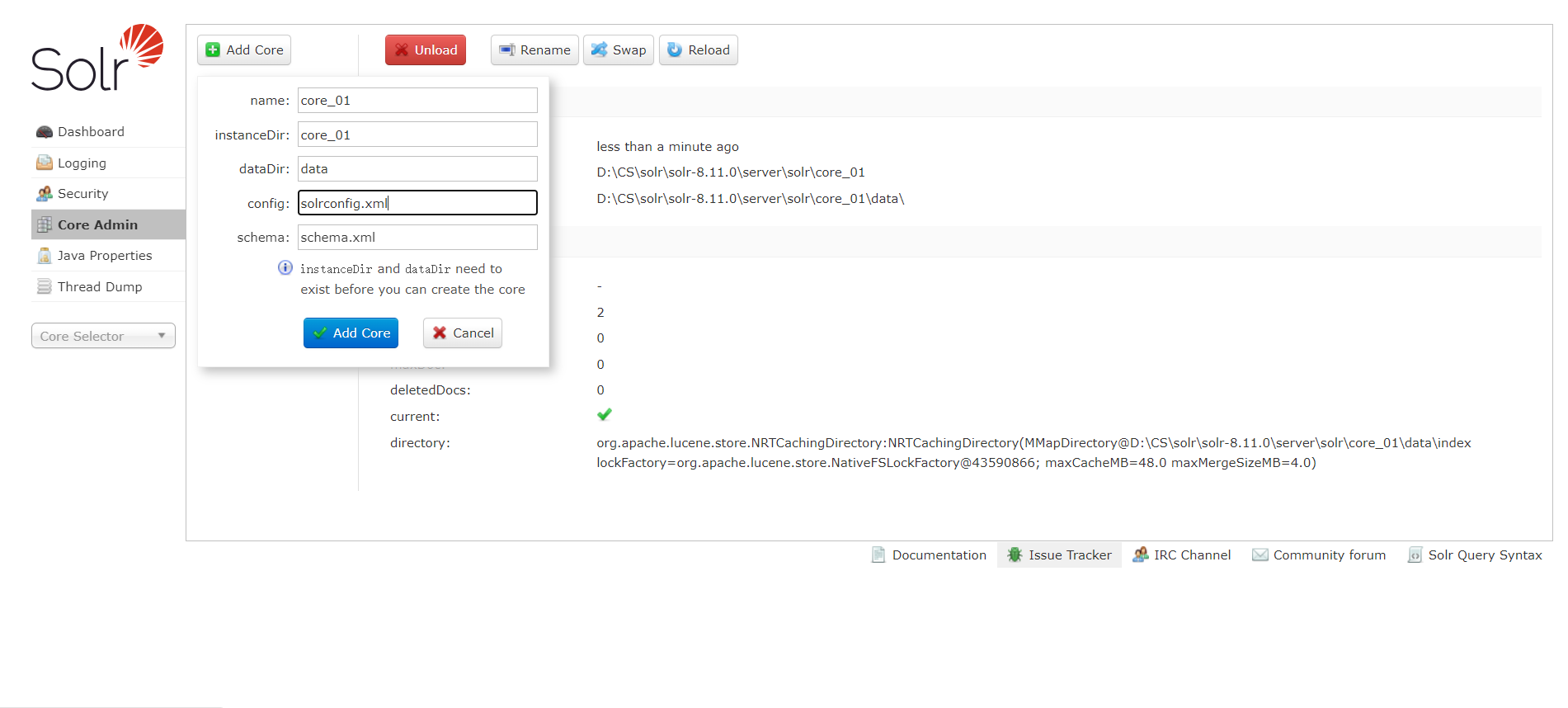
最后去管理界面创建就行啦

二:创建分词器 #
- 使用说明
- jar包下载地址:

- 历史版本:

<!-- Maven仓库地址 -->
<dependency>
<groupId>com.github.magese</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.1.1</version>
</dependency>
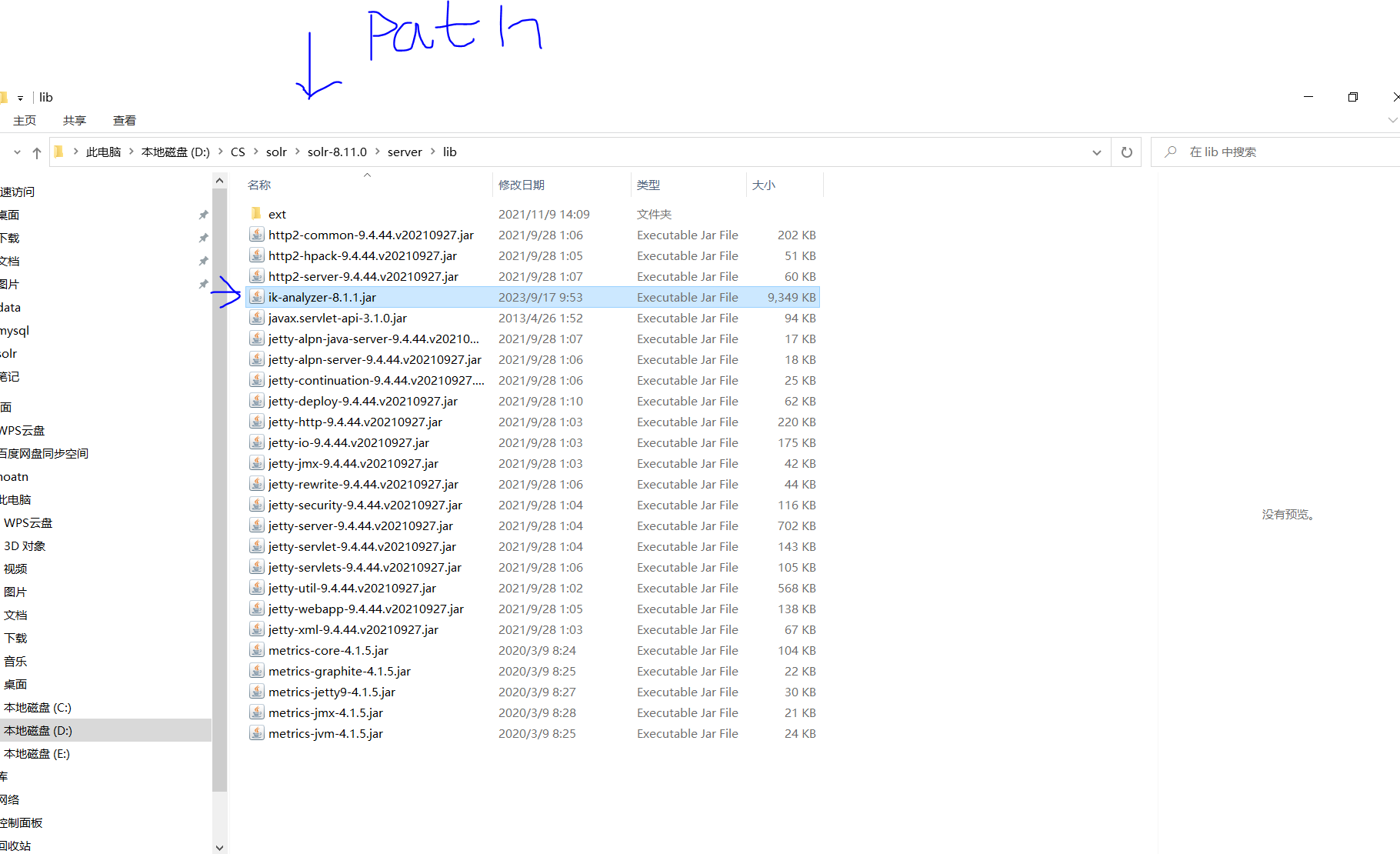
- 将ik分词器 放到lib中

- 找到managed-schema 文件 将ik分词器加进去
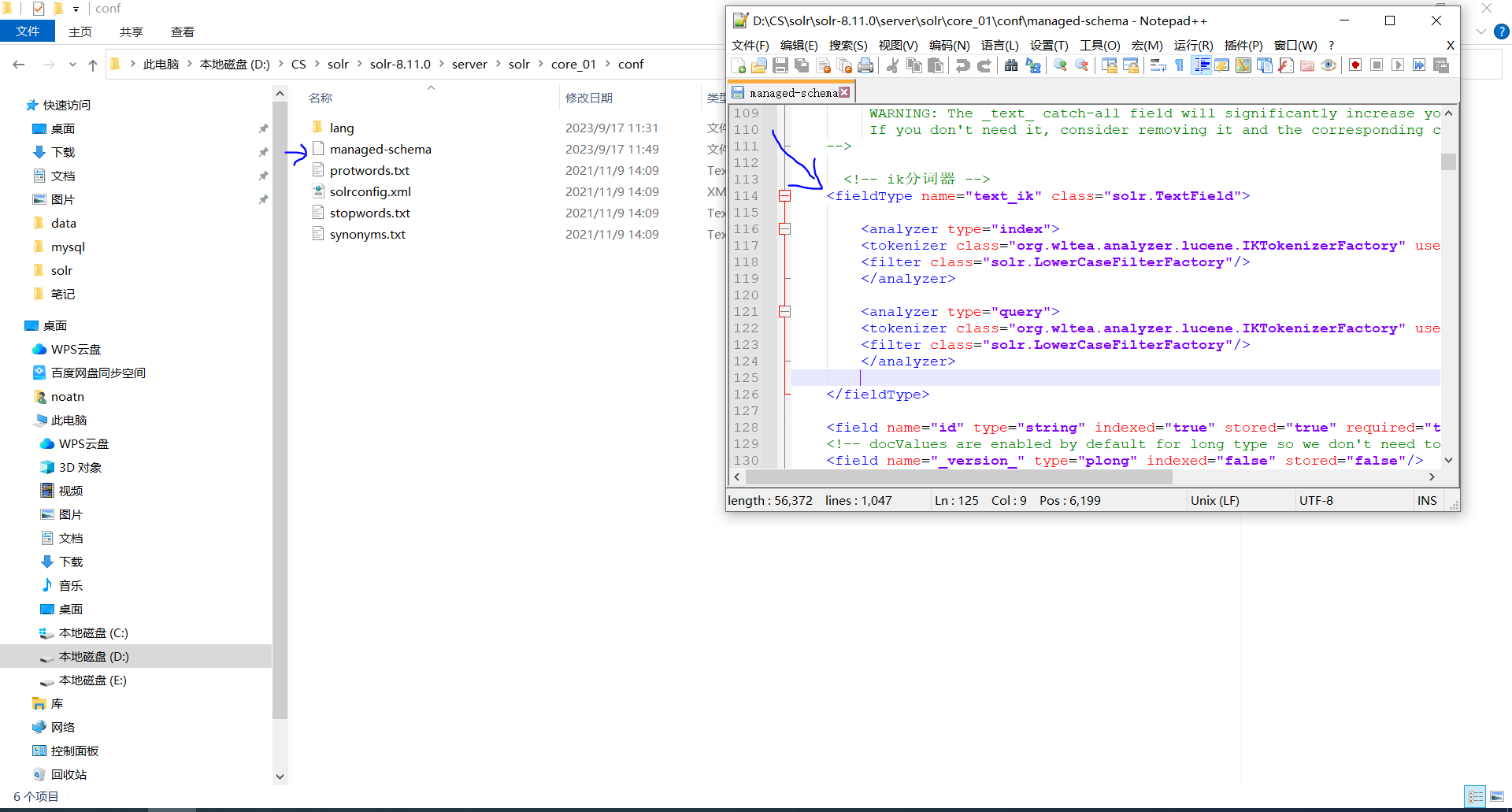

- 最后去管理界面测试效果
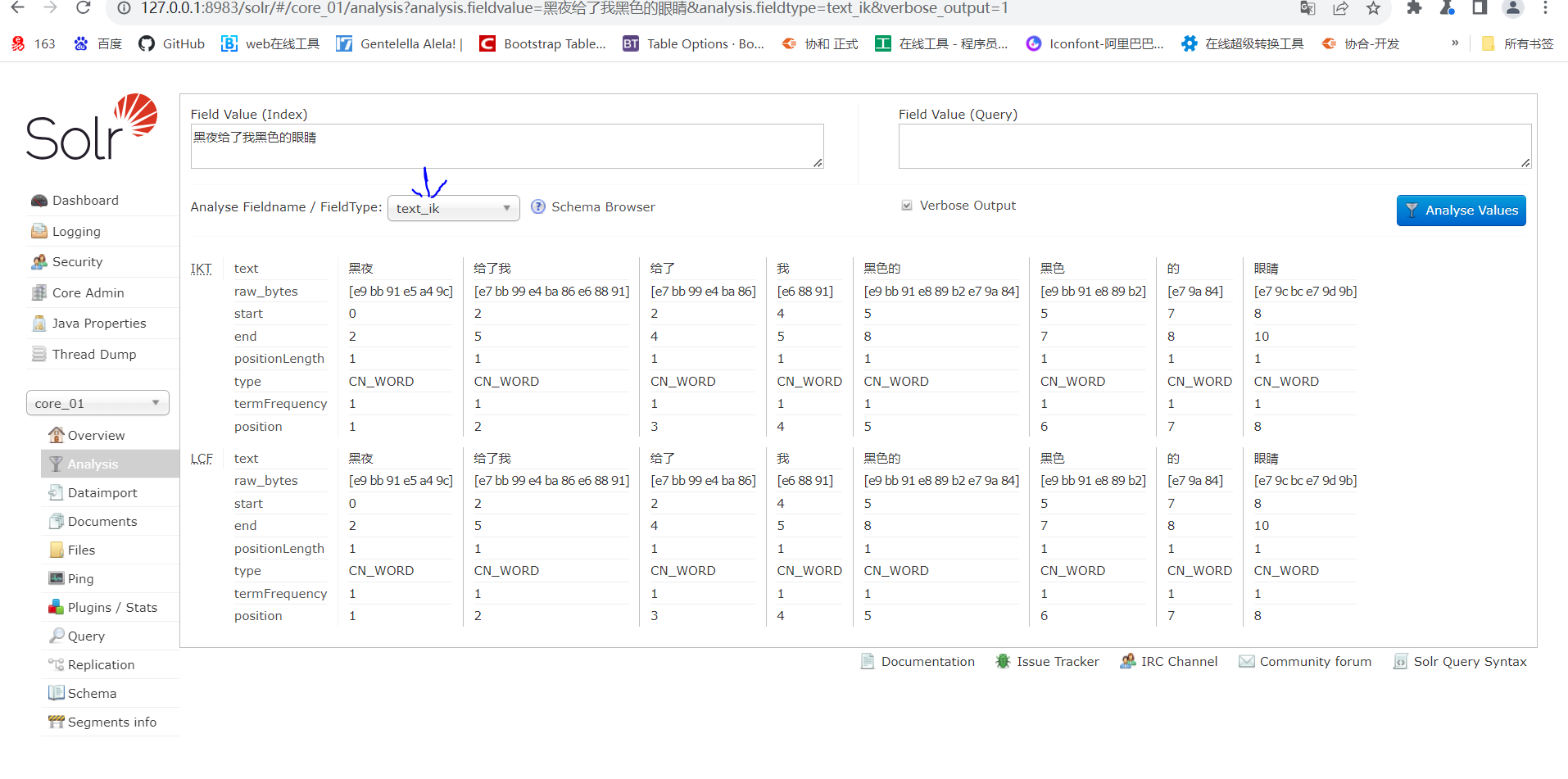

三:具体创建字段 #
类似 TextField 实际写为 solr.TextField ,BinaryField 写为 solr.BinaryField
| 类 | 描述 |
|---|---|
| BinaryField | 二进制数据。 |
| BoolField | 包含 true 或 false。第一个字符中的值:1,t或T被解释为true;第一个字符中的任何其他值都被解释为false。 |
| DoublePointField(旧TrieDoubleField) | 双字段(64 位 IEEE 浮点)。该类使用基于 “Dimensional Points” 的数据结构对double 值进行编码,从而可以非常有效地搜索特定的值或值的范围。对于单值字段,必须使用 docValues = “true” 来启用排序。 |
| IntPointField(旧TrieIntField) | 整数字段(32位有符号整数)。该类使用基于“Dimensional Points”的数据结构对int 值进行编码,可以非常有效地搜索特定值或值的范围。对于单值字段,必须使用 docValues = “true” 来启用排序。 |
| LongPointField(旧TrieLongField) | 长字段(64 位有符号整数)。该类使用基于 “Dimensional Points” 的数据结构对foo 值进行编码,从而可以非常有效地搜索特定值或值的范围。对于单值字段,必须使用 docValues = “true” 来启用排序。 |
| FloatPointField(旧TrieFloatField) | 浮点字段(32 位 IEEE 浮点)。该类使用基于“维度点”的数据结构对浮点值进行编码,可以非常有效地搜索特定的值或值的范围。对于单值字段,必须使用 docValues = “true” 来启用排序。 |
| TextField | 文本,通常是多个单词或标记。 |
| DatePointField(旧TrieDateField) | 日期字段。代表精确到毫秒的时间点,使用基于“维度点”的数据结构进行编码,可以非常有效地搜索特定值或值的范围。有关支持的语法的更多详细信息,请参阅使用日期部分。对于单值字段,必须使用 docValues = “true” 来启用排序。 |
| EnumFieldType(旧EnumField) | 允许定义枚举的一组值,这些值可能不易按字母或数字顺序(例如,严重性等级列表)排序。这个字段类型需要一个配置文件,它列出了字段值的正确顺序。有关更多信息,请参阅使用枚举字段一节。 |
| DateRangeField | 支持索引日期范围,还包括时间点实例(单毫秒(single-millisecond )持续时间)。有关使用此字段类型的更多详细信息,请参阅使用日期部分。请考虑使用这种字段类型,即使它只是用于日期实例,特别是当查询通常在 UTC 年/月/日/小时等边界时。 |
| UUIDField | 通用唯一标识符(UUID)。通过 NEW 值, Solr 将创建一个新的 UUID。注意:NEW 在使用 SolrCloud 时,配置一个默认值为 UUIDField 的实例对于大多数用户是不可取的(因为结果将是每个文档的每个副本将得到一个唯一的 UUID值。建议使用 UUIDUpdateProcessorFactory 在添加文档时生成 UUID 值。 |
| CollationField | 支持排序和范围查询的 Unicode 排序规则。ICUCollationField 是一个更好的选择,如果你可以使用 ICU4J。有关更多信息,请参阅 Unicode 归类部分。 |
| CurrencyField | 已弃用。改用 CurrencyFieldType。 |
| CurrencyFieldType | 支持货币和汇率。有关更多信息,请参阅使用货币和汇率部分。 |
| ExternalFileField | 从磁盘上的文件中提取值。有关更多信息,请参阅使用外部文件和进程一节。 |
| EnumField | 已弃用。改用 EnumFieldType。 |
| ICUCollationField | 支持排序和范围查询的 Unicode 排序规则。有关更多信息,请参阅 Unicode 归类部分。 |
| LatLonPointSpatialField | 纬度/经度坐标对;可能多值多点。通常用逗号指定为 “lat,lon” 顺序。有关更多信息,请参阅空间搜索部分。 |
| LatLonType | 已弃用。请考虑使用 LatLonPointSpatialField 来代替。一个单值的纬度/经度坐标对。通常用逗号指定为 “lat,lon” 顺序。有关更多信息,请参阅空间搜索部分。 |
| PointType | 一个单值的 n 维点。它既用于排序不是经纬度的空间数据,也用于一些更罕见的用例。(注:这与基于 “Point” 的数值字段无关)。请参阅空间搜索以获取更多信息。 |
| PreAnalyzedField | 提供一种发送到 Solr 序列化标记流的方法,可选地具有独立存储的字段值,并且在没有任何额外的文本处理的情况下存储和索引这些信息。PreAnalyzedField 的配置和用法在“使用外部文件和进程”一节中有介绍。 |
| RandomSortField | 不包含值。对此字段类型进行排序的查询将以随机顺序返回结果。使用动态字段来使用此功能。 |
| SpatialRecursivePrefixTreeFieldType | (简称 RPT)接受纬度逗号经度字符串或 WKT 格式的其他形状。请参阅空间搜索以获取更多信息。 |
| StrField | 字符串(UTF-8 编码的字符串或 Unicode)。字符串用于小型字段,不以任何方式标记或分析。他们有一个不到 32K 的硬限制。 |
| TrieField | 已弃用。这个字段用一个 type 参数来定义要使用的 Trie * 字段的特定类;改为使用适当的“Point Field”类型。 |
- managed-schema文件构成
<?xml version="1.0" encoding="UTF-8" ?>
<schema version="1.6">
<field .../> #字段
<dynamicField .../> #动态字段
<uniqueKey>id</uniqueKey> #唯一key的指定
<copyField .../> #拷贝字段
<fieldType ...> #字段存储类型
<analyzer type="index">
<tokenizer .../>
<filter ... />
</analyzer>
<analyzer type="query">
<tokenizer.../>
<filter ... />
</analyzer>
</fieldType>
</schema>
界面创建字段 #

- 没有添加字段的时候
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="default-config" version="1.6">
<!-- attribute "name" is the name of this schema and is only used for display purposes.
version="x.y" is Solr's version number for the schema syntax and
semantics. It should not normally be changed by applications.
1.0: multiValued attribute did not exist, all fields are multiValued
by nature
1.1: multiValued attribute introduced, false by default
1.2: omitTermFreqAndPositions attribute introduced, true by default
except for text fields.
1.3: removed optional field compress feature
1.4: autoGeneratePhraseQueries attribute introduced to drive QueryParser
behavior when a single string produces multiple tokens. Defaults
to off for version >= 1.4
1.5: omitNorms defaults to true for primitive field types
(int, float, boolean, string...)
1.6: useDocValuesAsStored defaults to true.
-->
<uniqueKey>id</uniqueKey>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!-- docValues are enabled by default for long type so we don't need to index the version field -->
<field name="_version_" type="long" indexed="false" stored="false"/>
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<!-- 索引时 -->
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<!-- 查询时 -->
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true"/>
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" docValues="true" multiValued="true"/>
<fieldType name="int" class="solr.IntPointField" docValues="true"/>
<fieldType name="ints" class="solr.IntPointField" docValues="true" multiValued="true"/>
<fieldType name="long" class="solr.LongPointField" docValues="true"/>
<fieldType name="plongs" class="solr.LongPointField" docValues="true" multiValued="true"/>
<fieldType name="binary" class="solr.BinaryField"/>
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="booleans" class="solr.BoolField" sortMissingLast="true" multiValued="true"/>
<fieldType name="date" class="solr.DatePointField" docValues="true"/>
<fieldType name="pdates" class="solr.DatePointField" docValues="true" multiValued="true"/>
<fieldType name="double" class="solr.DoublePointField" docValues="true"/>
<fieldType name="pdoubles" class="solr.DoublePointField" docValues="true" multiValued="true"/>
<fieldType name="float" class="solr.FloatPointField" docValues="true"/>
<fieldType name="floats" class="solr.FloatPointField" docValues="true" multiValued="true"/>
<!-- 文本紧密拆分 -->
<fieldType name="text_en_splitting_tight" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="false" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="0" generateWordParts="0" catenateAll="0" catenateWords="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="false" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="0" generateWordParts="0" catenateAll="0" catenateWords="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<!-- 普通文本 -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</schema>
- 添加了字段的时候
<?xml version="1.0" encoding="UTF-8"?>
<!-- Solr managed schema - automatically generated - DO NOT EDIT -->
<schema name="default-config" version="1.6">
<uniqueKey>id</uniqueKey>
<fieldType name="binary" class="solr.BinaryField"/>
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="booleans" class="solr.BoolField" sortMissingLast="true" multiValued="true"/>
<fieldType name="date" class="solr.DatePointField" docValues="true"/>
<fieldType name="double" class="solr.DoublePointField" docValues="true"/>
<fieldType name="float" class="solr.FloatPointField" docValues="true"/>
<fieldType name="floats" class="solr.FloatPointField" docValues="true" multiValued="true"/>
<fieldType name="int" class="solr.IntPointField" docValues="true"/>
<fieldType name="ints" class="solr.IntPointField" docValues="true" multiValued="true"/>
<fieldType name="long" class="solr.LongPointField" docValues="true"/>
<fieldType name="pdates" class="solr.DatePointField" docValues="true" multiValued="true"/>
<fieldType name="pdoubles" class="solr.DoublePointField" docValues="true" multiValued="true"/>
<fieldType name="plongs" class="solr.LongPointField" docValues="true" multiValued="true"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true"/>
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" docValues="true" multiValued="true"/>
<fieldType name="text_en_splitting_tight" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="false" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="0" generateWordParts="0" catenateAll="0" catenateWords="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" expand="false" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="0" generateWordParts="0" catenateAll="0" catenateWords="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<field name="_version_" type="long" indexed="false" stored="false"/>
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="cover" type="text_general" uninvertible="true" indexed="true" stored="true"/>
<field name="cover_x" type="int" uninvertible="true" docValues="true" indexed="true" stored="true"/>
<field name="cover_y" type="int" uninvertible="true" docValues="true" indexed="true" stored="true"/>
<field name="episodes_info" type="string" uninvertible="true" indexed="true" stored="true"/>
<field name="is_new" type="booleans" uninvertible="true" indexed="true" stored="true"/>
<field name="playable" type="boolean" uninvertible="true" indexed="true" stored="true"/>
<field name="rate" type="double" uninvertible="true" indexed="true" stored="true"/>
<field name="title" type="text_ik" uninvertible="true" indexed="true" stored="true"/>
<field name="url" type="string" uninvertible="true" indexed="true" stored="true"/>
</schema>